生物统计学(biostatistics)
第一章绪论
定义:用数理统计的原理和方法来分析和解释生物界各种现象和试验调查资料的一门学科
生物的特点:随机性、变异性、复杂性
常用统计学术语
•同质(homogeneity):根据研究目的所确定的观察单位其性质应大致相同。
•变异(variation):即使性质相同的事物,由于存在个体差异,同一指标的测量结果也不同。
•总体(population):具有相同性质的个体所组成的集合,指研究对象的全体。(有限总体、无限总体)
•个体(individual):组成总体的基本单位。
•样本(sample):从总体中抽出的有代表性的若干个体所构成的集合。(通常把n≤30的样本叫小样本, n>30的样本叫大样本)
•参数(参量)(parameter):对一个总体特征的度量。•常用希腊字母表示μ、σ
•统计数(统计量)(statistic):由样本计算所得的数值。•常用英文字母表示s、x
•变量(variable):相同性质的事物间表现差异性的某项特征或者性状。
•常量(constant):对总体来说不会变化的变量,例如总体平均数等。
•因素(factor):试验中所研究的影响试验指标的原因或原因组合。
•(因素)水平(level):每个因素的不同状态。
处理(treatment)与重复(repetition)、效应(effect)与互作(interaction)、准确性(accuracy)与精确性(precision)、误差(error)与错误(mistake)、概率(probability)
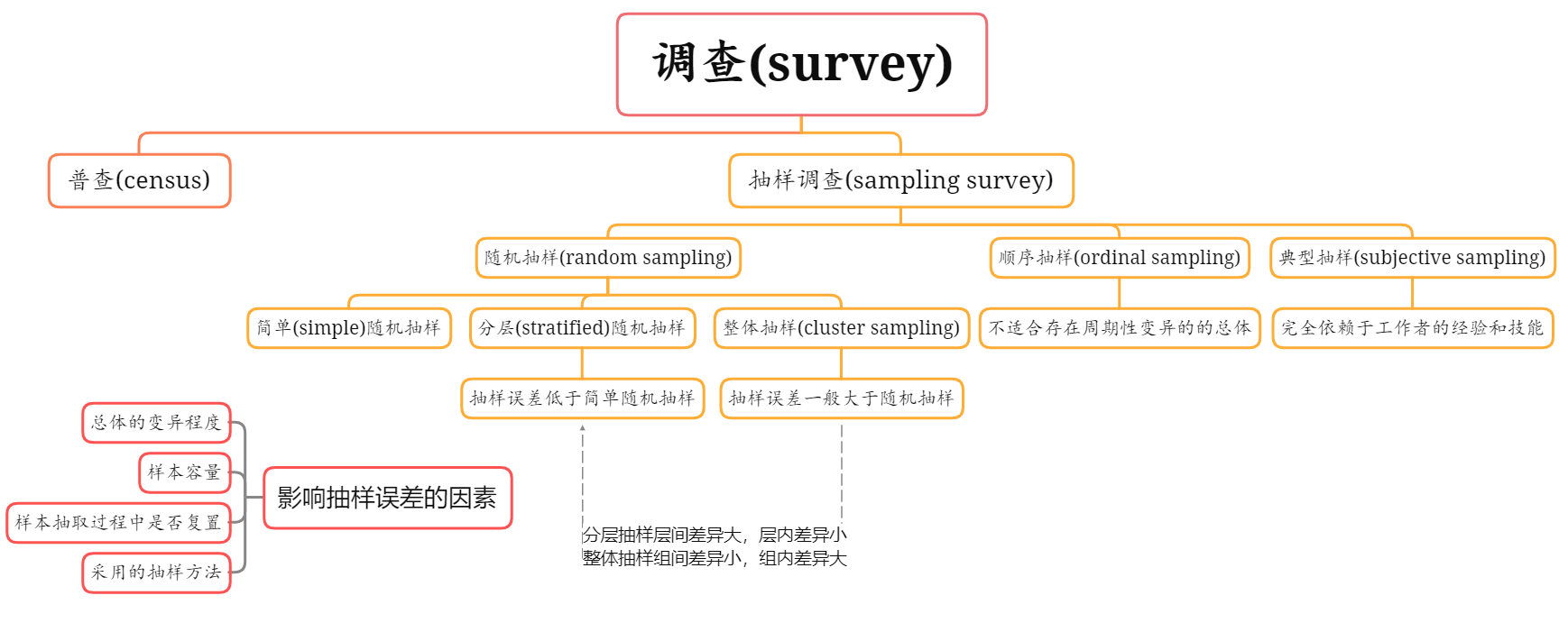
生物统计学的内容
试验设计(experimental design)
•取样是否有代表性?是否随机?对照、重复、几个因素、几个水平、是否排除无关因素
统计分析(statistical analysis)
| 数据整理 | 数据检查 | 变量转换 | 数据分布 |
|---|---|---|---|
| 统计描述 | 统计指标 | 统计表 | 统计图 |
| 统计推断 | 参数估计 | 假设检验 | 方差分析等 |
•SPSS(statistical package for the social sciences)
第二章资料整理与特征数计算
资料的类型
资料(data):在生物学试验及调查中能够获得大量的原始数据,是在一定条件下对某种具体事物或现象观察的结果,称之为资料。资料就是变量的值。
| 对某种现象只能观察不能测量的资料 | 一般是由计数和测量得到的。 |
|---|---|
| 质量性状(qualitative character)资料 | 数量性状(quantitative character)资料 |
| 花瓣的颜色 | 鱼尾数,玉米籽粒数 |
| 治疗疾病的痊愈,好转 | 高度,重量 |
•生物统计学归根结底就是用样本来估计总体的问题,所以统计分析的基础就是样本的搜集。
试验(experiment):•对一定数量的有代表性试验单位,在一定条件下进行有探索性的研究工作。遵循随机、重复和局部控制三项基本原则
资料的整理
更正缺失数据、重复值和异常值
利用SPSS软件绘制
频数分布表(frenqucy table)、条形图(bar chart)、直方图(histogram)、饼图(pie chart)、散点图(scatter chart)
资料特征数的计算
变量的分布具有两个明显的基本特征
集中性(centrality)•反映集中性的特征数是平均数。
离散性(discreteness)•反映离散性的特征数是变异数。
平均数(mean):算术平均数、中位数、众数、几何平均数(geometric mean)
中位数(median)、众数(mode):适用于服从偏态分布的数据
变异数(variance):极差(range)、方差(variance)、标准差(standard deviation)、四分位数间距(quartile range)、变异系数(coefficient of variability)
标准差是衡量变量资料变异程度的最好指标
•1. 标准差受到所有观测值的影响。
•2. 将各观测值减去一个常数a,其标准差不变;将各观测值乘以一个常数a,其标准差扩大了a倍。
•3. 标准差和平均数一样,与观测值具有相同的单位。
•4. 因为利用了算术平均数,所以同样不适合偏态分布。
Q1,Q2和Q3恰好把资料分成四个相同大小的组分,所以叫四分位数,•四分位数间距Q=Q3-Q1。
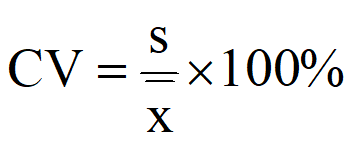
**变异系数没有单位**:标准差除以样本平均数乘以100%
算术平均数总是大于几何平均数
第三章概率分布
生物统计学最主要的任务是用样本统计数来推断其所属总体的参数
从同一总体中随机抽取样本,每次得到的样本不会完全相同,用不同样本去推断同一总体将得到不同的结论,如何判断这些结论的可靠性
•这些推断的基础是关于概率分布的基本知识,以及抽样分布。
概率基础知识
•必然事件**(certain event),以U表示。**
•不可能事件**(impossible event),以V表示。**
•随机事件**(random event,简称事件),指在某些确定条件下,因为偶然因素的影响而可能出现也可能不出现的现象。**
和事件(sum event):A+B至少有一件事发生
积事件(product event):A·B多个事件同时发生
互斥事件(mutually exclusive event):A·B=V,不可能同时发生
对立事件(contrary event):A+B=U,A·B=V,必有一件事发生
完全事件系(complete event system):A**1+A2+……+An=U,Ai·Aj=V(当i不等于j时)**,多个事件两两相斥
独立事件(independent event):两者毫无关系
加法定理P(A+B)=P(A)+P(B)-P(A·B)
乘法定理P(A·B)=P(A|B)·P(B)= P(B|A)·P(A)
频率(frequency):即某事件发生的次数除以重复试验次数
概率(probability):随着重复试验次数不断增大,某事件发生的频率越来越接近某一固定值p,p就定义为该事件发生的概率。(一般情况下,因为重复试验的次数是有限的,所以频率只是概率的一个近似值。)
•频率是试验中真实观察到的概率,概率是理论上的频率。
•频率是样本的统计数,概率是总体的参数。
概率分布(已知总体推样本)
概率分布**(probability distribution):**随机变量的取值与取这些值的概率之间的对应关系
离散型变量的分布:二项分布、泊松分布……
连续型变量的分布:正态分布、t分布、卡方分布、F分布
二项分布(binomial distribution):结果只有两种情况的事件组成的总体的概率分布,试验具有重复性和独立性 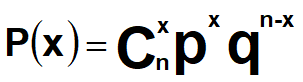
泊松分布(poisson distribution):就是p值很小,但n值很大的特殊情况的二项分布
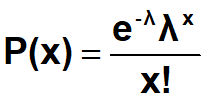
•泊松分布的平均数和方差均为λ。
•二项分布当p<0.1且np<5时,可以用泊松分布来近似计算。
•泊松分布的形状参数λ无限增大时,泊松分布接近正态分布。
正态分布(normal distribution):随机误差****一般服从正态分布
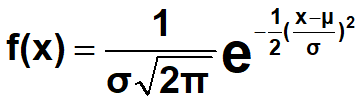
•该正态分布记为N(μ, σ2),其中μ是正态分布的平均数,σ是正态分布的标准差。
•变量落在 (μ-σ, μ+σ)范围内的概率是68.26%;
•变量落在(μ-2σ, μ+2σ)范围内的概率是95.45%。
μ决定f(x)的位置,μ增大,曲线右移。
σ决定f(x)的性状,σ增大,曲线越宽矮。
•P(-1.96<x<1.96)=0.95•P(-2.58<x<2.58)=0.99
生物统计学的研究包含两个过程:从总体抽取样本的过程,从样本统计数推断总体参数的过程
重置抽样也称“回置抽样”、“重复抽样”或“有放回的抽样”
若只有一个总体
样本平均数分布性质
(1)样本平均数分布的平均数等于总体平均数
(2)样本平均数分布的方差等于总体方差除以样本容量
| 只有一个总体 | 有两个总体 |
|---|---|
| u分布(标准正态分布) | 已知总体方差时,u检验可以用于比较总体平均数 |
| t分布(从平均数μ,标准差未知的正态总体中,随机抽取含量为n的样本) | 已知样本方差时,t检验可以用于比较总体平均数 |
| 卡方分布(μ,σ的正态总体中,独立随机地抽取k个含量为n的样本) | 已知两个总体的标准差时,F检验可以用于比较总体的方差 |
u分布:当μ=0,σ=1时,N(0,1)被称为标准正态分布,又称为u分布,F(u)
t分布:不服从正态分布,服从自由度为n-1,是从平均数为μ,==样本容量不大==*==标准差未知==*的正态总体中,独立随机地抽取含量为n的样本产生的分布。
卡方分布:从平均数为μ,标准差为σ的正态总体中,独立随机地抽取k个含量为n的样本
•卡方分布的取值范围是0到正无穷;
•曲线不对称,峰值偏左(特别在df=1时,曲线以y轴为渐近线)。
•随着自由度df增大,卡方分布趋于左右对称直至正态分布。
若需要比较两个总体
样本平均数差数分布的基本性质
(1)样本平均数差数的平均数等于总体平均数的差数(或样本平均数分布的平均数的差数)
(2)样本平均数差数的方差等于总体方差除以各自样本容量之和(或两样本平均数方差之和)
设从一正态总体N(μ,$σ^2$)中随机抽取样本容量为$n_1$和$n_2$的两个独立样本,其样本方差为$s_1^2$和$s_2^2$,则定义$s_1^2$和$s_2^2$的比值为F:
$$
F=
\frac{s{_1}{^2}}{s{_2}{^2}}
$$
•在已知总体方差时,u检验可以用于比较总体平均数。
•在已知样本方差时,t检验可以用于比较总体平均数。
若两个总体的标准差已知

•当σ1与σ2相等时,F可以简化为两个样本方差的比值。
•F检验可以用于比较总体的方差。
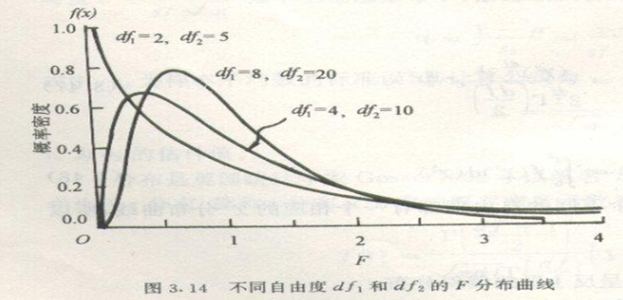
•F分布的取值范围是0到正无穷;
•F分布的平均数趋向1;
•曲线不对称,峰值偏左(特别在df1=1或2时,曲线以y轴为渐近线)。
•曲线性状仅取决于df1和df2。
第四章统计推断(已知样本推总体)
上一章我们讨论了已知总体的时候样本的特征,即抽样分布。
本章我们来讨论已知样本的时候如何推断总体的特征,主要任务是分析差异产生的原因,是随机误差导致的,还是一些处理效应导致的。
假设检验的原理与方法
假设检验(hypothesis test):也叫显著性检验(significance test),是根据总体的理论分布和小概率原理,对==未知或不完全知道的总体==提出==两种==彼此对立的假设,然后由样本的实际结果,经过一定的计算,做出在一定概率意义上应该接受哪种假设的推断。
假设检验的步骤
1. 提出假设
零假设(null hypothesis)也称无效假设,是指处理效应没有产生真实的差异,即差异都是随机误差导致的。
备择假设(alternative hypothesis),是指处理效应产生了真实的差异。
2. 确定显著水平
显著水平(significance level)是人为规定的小概率界限,用α表示,常用取值是0.05或0.01,特殊情况时也可以取其他值。
α也是假阳性发生的概率,及I型错误的发生率
3. 计算统计数与相应的概率
在假定零假设正确的前提下,选择恰当的抽样分布相关公式计算标准化后的统计数,然后查表找到对应的概率累积函数值。
4. 推断是否接受假设
推断的基础是小概率原理,即认为小概率事件在一次抽样试验中几乎是不可能发生的
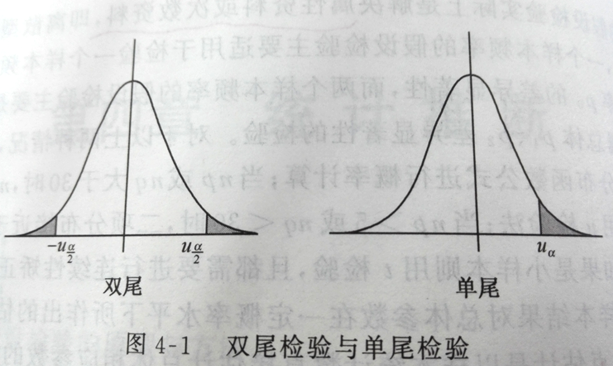
双尾检验和单尾检验
| 零假设 | 备择假设 | |
|---|---|---|
| 差值等于0 | 差值不等于0 | u**<-$\frac{u{_α}}{2}$和u>$\frac{u{_α}}{2}$两个区域,所以叫双尾检验** |
| 差值大于0 | u**>$u_α$区域**,单尾检验 | |
| 差值小于0 | u**<-$u_α$区域**,单尾检验 | |
| ==单尾检验灵敏度高==,一般用单尾 |
假设检验的两类错误

I型错误,也常称为α错误,弃真错误或==假阳性==错误。发生概率α
II型错误,也常称为β错误,取伪错误或==假阴性==错误。概率与两个总体的分布情况有关,也与显著水平α有关
如何减少II型错误:
(1)α越大,β越小(不可取)
(2)两个μ的差值越大,β越小(比如采用更有效的药物)
(3)备择曲线的σ值越小,β越小(样本越集中)
(4)为了少犯β错误,增加样本容量是最有效的办法
样本方差的同质性检验
方差的同质性(又称方差齐性,homogeneity of variance),就是指各个总体的方差是相同的
•方差同质性检验就是要从各样本的方差来判断其总体方差是否相同。
| 比较一个样本所属总体的方差与参考总体的方差有无显著差异 | 比较两个样本所属总体的方差与参考总体的方差有无显著差异 |
|---|---|
| 卡方检验 | F检验 |
一、比较一个样本所属总体的方差与参考总体的方差有无显著差异,使用卡方检验
例题•已知正常农田铅浓度的方差0.065(μg/g)2,某农田经抽样8份,测定其铅浓度的方差0.15(μg/g)2,问该农田铅浓度的方差与正常农田是否相同。
•(1)零假设两者铅浓度的方差无差别,即某农田的铅浓度的方差正常。
•(2)显著性水平α取0.05
•**(3)计算**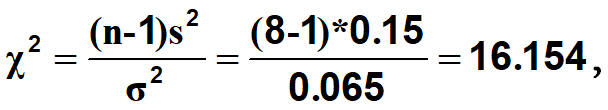
• df=n-1=7时,卡方检验右尾检验的拒绝区是卡方大于14.07,16.154落在拒绝区内。
•(4) 结论:拒绝零假设,认为两者铅浓度的方差有显著差别,且该农田铅浓度的方差高于正常值。
二、 比较两个样本所属总体的方差与参考总体的方差有无显著差异,使用F检验
例题•小麦品种甲抽样10次,其千粒重的方差是22.933,小麦品种乙抽样10次,其千粒重的方差是2.933,问两个品种的千粒重的方差是否相同。
•(1)零假设两者千粒重的方差无差别。
•(2)显著性水平α取0.05。
•(3)计算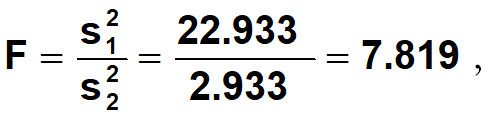
• df1=n-1=9,df2=n-1=9时,F检验右尾检验的拒绝区是F>3.18,7.819落在拒绝区内。
•(4) 结论:拒绝零假设,认为两者千粒重的方差有显著差别,且品种甲的方差高于品种乙。
样本平均数的假设检验
| 一个样本平均数的假设检验总结 | 两个样本平均数的假设检验总结 |
|---|---|
| 比较样本所属总体和参考总体的平均数,且参考总体的方差已知,用u检验 | 比较两个样本所属总体的平均数,且两个总体的方差已知,用u检验 |
| 比较样本所属总体和参考总体的平均数,且参考总体的方差未知,用t检验,但在样本容量较大(≥30)时,t检验和u检验几乎没有区别 | 比较两个样本所属总体的平均数,且两个总体的方差未知,但在两个样本容量都较大(≥30)时,可以用u检验简化计算 |
| 比较两个样本所属总体的平均数,且两个总体的方差未知,样本容量较小时应使用t检验,可以分成三种情况:==方差相等,样本容量相等或两者均不相等== | |
| 对于成对数据,其实可以转化成一个样本平均数的假设检验,服从df=n-1的t分布,当n足够大时,可以简化为u检验。 |
参数估计
参数估计是指由样本结果对总体参数在一定概率水平下所做出的估计。
其实,参数估计就是统计推断相反的运算过程;
统计推断是已知μ,求u或t的值;
参数估计就是已知u或t,求μ的值。
例题•测得某批25个小麦样本的平均蛋白质含量为14.5%。
•(1)正常小麦的蛋白质含量为14%,标准差为2.50%,请问该样本是否正常?
•(2)求该批蛋白质含量的95%置信区间。
•(1) 零假设该样本蛋白质含量等于14%,备择假设该样本蛋白质含量不等于14%。
•显著性水平α取0.05
•标准化计算
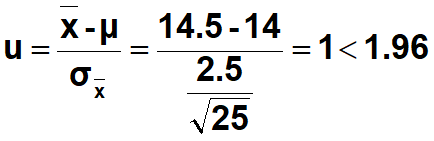
接受零假设,该样本与正常小麦样本无差别
•(2) 求95%置信区间,即
•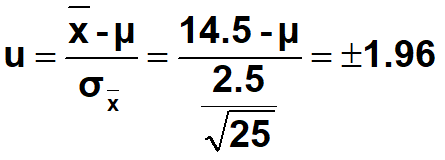
•经计算可得μ=13.52或15.48。
•即该批蛋白含量的95%置信区间为13.52%~15.48%(区间估计),也可以写成14.5±0.98(点估计)。
•显然这个区间包括了14%,从另一个角度验证了上一小题的结论是正确的。
第五章卡方检验
不是所有的样本都可以计算平均数和方差的;
例如属性资料的样本,和一些计数资料的样本
| 属性资料 | 计数资料 |
|---|---|
| 用1. 统计次数法;2. 评分法 | 服从二项分布,则可以利用二项分布的公式来研究其概率分布,有时可近似成正态分布 |
| 将其转化为计数资料 | 无论是否服从二项分布,都可以使用χ2检验来研究其概率分布 |
χ2检验(chi-square test)
①一个样本的方差同质性检验;
②适合性检验;只有右尾检验
③独立性检验;只有右尾检验
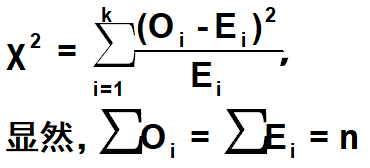
•对于计数资料或属性资料,其观测值Oi与理论值Ei通过以上公式计算后,应该趋向于服从自由度df=k-1的χ2分布。
•如果观测值Oi偏离理论值Ei,χ2增大,与χ2分布只有右侧拖着长尾吻合;
χ2检验的步骤
•1. 提出零假设:观测值等于理论值,或者说两者的差异是由抽样误差引起的;备择假设:观测值不等于理论值,即两者的差异是真实存在的。
•2. 确定显著水平α,一般取0.05或0.01。
•3. 根据公式计算χ2。
•4. 进行统计推断。从附表4查出χ2α的值,如果χ2大于χ2α,则拒绝零假设;否则接受零假设。
PS:
理论值非常小时,上式计算的χ2将偏离χ2分布,所以在==Ei≤5时,需要进行并组==;
在==自由度df=1时==,需要进行连续性矫正;当df>1时,是否进行连续性矫正差别不大。
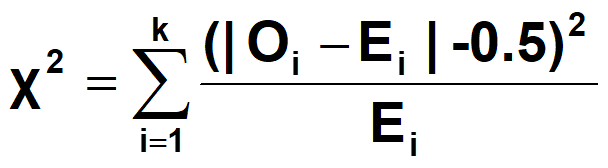
| 适合性检验compatibility test | 独立性检验 |
|---|---|
| 比较观测值与理论值是否符合的假设检验,也叫拟合优度检验(goodness of fit test) | 独立性检验是研究两个或两个以上因子彼此之间是相互独立的还是相互影响的一类统计方法,也理解成两个样本之间的适合性检验。 |
二项分布的适合性检验根据二项分布公式计算理论频数 注意理论值≤5时应该并组。 ==通过样本估计了一个参数,需要df-1== ==通过样本估计了一个参数,需要df-1== |
自由度df=(r-1)(c-1) |
正态分布的适合性检验先根据频数分布表,计算样本的平均数和方差 ==通过样本估计了两个参数,df-2== ==通过样本估计了两个参数,df-2== |

